I am currently at a presentation of Patrick Schwanke, Quest Germany, regarding easy and high speed connect between NoSQL and Oracle Databases. Not really what I planned but as mentioned by Alex Nuijten in an earlier post, unstructured data and it’s handling is gaining ground, so I thought it would a good start do start Oracle Open World with a new topic.

Some things NoSQL is good in is pointers like, very many parallel users, processes and consistency, at any point in time all nodes see the same data, availability, failure of one / several nodes doesn’t effect others, and/or partition tolerance, that is, even if some nodes cannot communicate with each other any more, the system keeps responsive.
The challenge is to bring those two world together, the Oracle relational environment and the noSQL realm. Patrick addressed two options to address these, speaking SQL to a noSQL environment of use specialized connecters. While using SQL against a noSQL environment, most of the time a data hub is used to translate the SQL to the underlying value-key noSQL environment. Apparently Toad for Cloud can be used as a client for this, which then calls to these data hubs while using SQL, gets translated by the data hub and then those calls are passed on to environment like MongoDB. This “data hub” can be a mySQL environment that hooks into the noSQL environment.
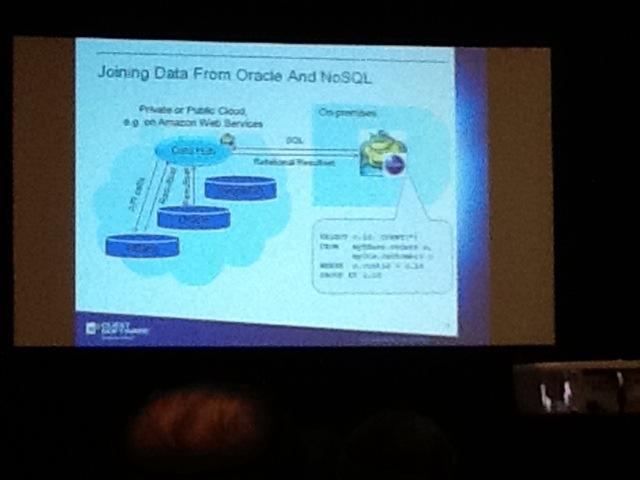
Depending on methods used, joins and other operations are done in the data hub layer or in the database layer. When multiple database flavors are in place between the client and the database layer result sets from relational and/or noSQL sources will have to be normalized in a super set table construct in the data hub environment so data set results can be queried.
The second solution, using the specialized connectors, for example, Cloudera’s SQOOP (Hadoop based), have a generic approach regarding eg. connections, via JDBC.

For Oracle this might be sup optimal, for example not being able to optimize the properly using parallelization or the proper CBO optimization. To do this better, Quest has created its own connector, the Quest Data connector for Hadoop, to optimize those processes explicitly for use with a Oracle database and being more aware regarding partitioning or support for RAC clusters. This Quest connector will be free to use.
In all a nice overview presentation, start, for my attendance of this years Oracle Open World conference.